Los que tengan edad para saber qué era una radio de dos pletinas valorarán la diferencia entre una copia analógica y una digital: una copia analógica se va deformando con cada copia (por el inevitable ruido) hasta llegar a ser inservible.
¿Pasará lo mismo con las imágenes digitales codificadas en formato JPEG? Veremos que, sorprendentemente, ¡a veces sí y a veces no!
¿Qué es el formato JPEG?
Una imagen digital, para un ordenador, no es más que una ristra rectangular de píxeles. El color de cada píxel se debe representar con números enteros y como sabrás se muestran por separado los colores rojo, verde y azul o RGB por sus siglas en inglés. Normalmente se usa un rango de números desde 0 hasta 255 para cada uno de estos colores por conveniencia, ya que así cada píxel ocupa 24bits (o sea 3 bytes exactos). En esto consistiría una imagen en bruto, o raw, y aunque sea la forma en que se muestra por pantalla ocupa una barbaridad de memoria y se tardaría mucho en enviar imágenes por Internet. Por eso se inventaron muchas formas de comprimirlas y que no ocupasen tanto.
Uno de esos formatos es el JPEG. Lo primero que se hace en él es transformar de RGB a otro espacio de color (el YCbCr), de forma que se le pueda dar más importancia a la intensidad o brillo (Y) que a las componentes de color (Cb, Cr). Esto se hace así porque el ojo humano es menos sensible a colores que al brillo, por lo que JPEG dará prioridad a este último.
Después, se realiza lo que se conoce como «compresión con pérdidas»: usando una compleja teoría matemática, la transformada del coseno discreta (DCT), se analizan las componentes de frecuencia de la imagen en cada bloque de 8×8 píxeles. La siguiente imagen te ayudará a entender qué quiere decir esto: cada bloque de 8×8 píxeles se aproxima por la suma ponderada de varios de estos bloques patrón:
Funciones base de la DCT. Cada bloque de 8×8 píxeles separado por líneas rojas es una función base. (Créditos)
En teoría, sumando infinitos cuadritos de esos podríamos obtener cualquier imagen, da igual lo compleja que sea. A los que conozcan la teoría de transformada de Fourier todo esto les sonará mucho (y sería lógico porque se trata de exactamente lo mismo pero con otras funciones bases).
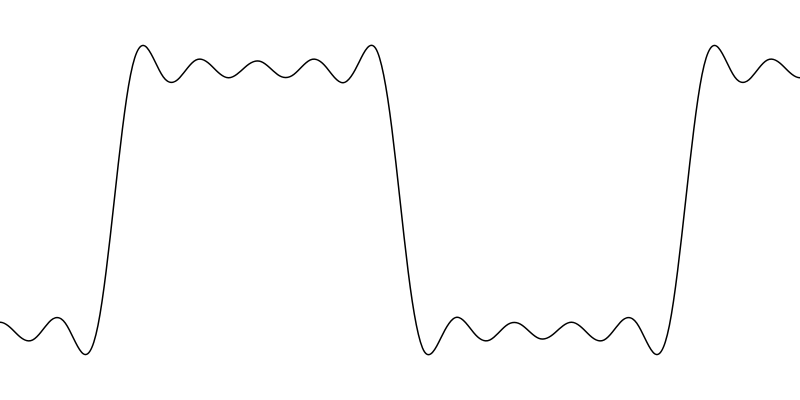
Pero si queríamos comprimir una imagen y necesitamos infinitas sumas, las cuentas no nos cuadran, ¿verdad?. En realidad lo que se hace es, en función de un importante parámetro que se llama calidad del JPEG (definido entre 0 y 100), quedarnos sólo con unos pocos de esos cuadritos elementales (las componentes principales). Para visualizarlo mejor, haciendo la equivalencia con una señal unidimensional en vez de una imagen (quizás más difícil de ver), sería aproximar un tren de pulsos perfectamente rectangular por esto:
Si de un pulso rectangular sólo te quedas con las primeras componentes frecuenciales te queda algo así. (Créditos)
En resumen: la calidad, ese número de 0 a 100 que a veces nos sale a la hora de guardar un fichero JPEG, indica con cuántas componentes frecuenciales de la DCT queremos quedarnos y cuantas descartar. Eso sí, ni siquiera para un valor máximo de 100 se guardarán todas las componentes, por lo que JPEG es un formato que siempre presenta pérdidas; eso sí, casi imperceptibles a simple vista.
Experimento 1: Con una fotografía
Vamos a probar qué pasaría si tomamos una foto, como ésta de un muñeco de nieve (¡no, no es de Málaga!):
y la grabamos a JPEG, la cargamos y la volvemos a guardar a JPEG, una y otra vez. Y todo eso, a distintos niveles de calidad.
Obviamente, nadie debería hacer eso nunca: si quieres hacer una copia digital de una imagen ¡lo lógico es copiar directamente el fichero JPEG original y no recodificarlo de nuevo!. Pero aún así, tenía curiosidad por esta serie de experimentos, así que vamos a ver los resultados.
Para este primer caso de una fotografía, el resultado es sorprendente: para casi todos los niveles de calidad, en como mucho 20 ciclos de re-codificación se llega a un punto de equilibrio del que ya la imagen no empeora.
Observando detenidamente estas dos ampliaciones, para el peor caso que he probado (calidad Q=50), apenas se nota el empeoramiento:
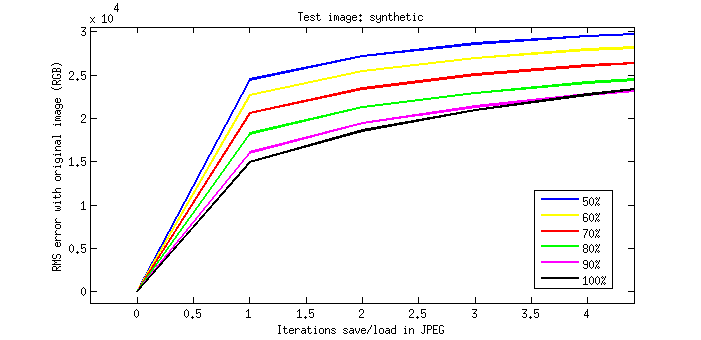
Para medir el error introducido con cada ciclo de re-codificación, he calculado el error cuadrático medio (RMS) entre las imágenes recodificadas y la original para cada calidad Q.
Y éste es el resultado:
Curiosamente, la mejor calidad (Q=100) no es la que menos error mete tras más de 5 recodificaciones, aunque evidentemente en la primera iteración se cumple estrictamente que a mayor Q, menor error.
En conclusión: para fotos reales, JPEG se porta muy bien, incluso tras varias re-codificaciones.
Experimento 2: Con una imagen sintética
Probamos ahora con una imagen sintética, que les pone las cosas más difíciles a JPEG al existir muchas transiciones abruptas de colores y bordes muy nítidos; cosas que en fotos reales casi nunca se dan.
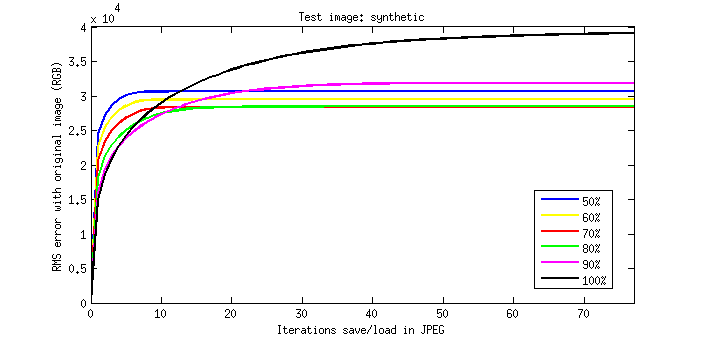
En este caso, incluso para la máxima calidad (Q=100) el color se va perdiendo rápidamente, y algunos bordes se van diluyendo:
Repitiendo la gráfica de antes, vemos que para las primeras re-codificaciones se cumple que a mayor calidad menor error, como cabría esperar:
Pero a largo plazo, cuando se repiten docenas de ciclos, el error continúa incrementándose más y más, llevándose la palma del mayor error… ¡¡la codificación a máxima calidad de Q=100!!
Dejo a los lectores que piensen por qué precisamente a mayor calidad (Q), mayor error con cada recodificación 😉
¿Qué lecciones aprendemos de esto?
Para codificar imágenes sintéticas, ¡evita JPEG!. Usa algún otro formato sin pérdidas, como GIF o PNG.
Y en cualquier caso, no codifiques en JPEG una imagen ya decodificada, como por ejemplo una captura de pantalla, ya que el error no parará de aumentar.
Experimento 3: Con una imagen sintética en movimiento
Y ya para poner las cosas extremadamente difícil a JPEG, he repetido el mismo experimento pero ahora desplazando la imagen 1 píxel hacia la derecha en cada re-codificación. Veamos el vídeo (recomiendo poner el vídeo a la máxima resolución):
¡Eso son pérdidas, sí señor!
Por cosas como ésta es por lo que en algoritmos de compresión de vídeo se incluye un keyframe cada X imágenes de vídeo.
Termino con una pregunta para reflexionar: ¿a qué creéis que se debe que en imágenes estáticas se llegue a un equilibrio tras unas docenas de re-codificaciones, pero eso no ocurra con el vídeo?









{kind=link}
{kind=link}