Como sabrás, en Estadística asignamos a cada posible evento X una probabilidad P(X), un número entre cero (nunca ocurrirá) y uno (seguro que ocurrirá). Es mucho menos conocida una peculiar excepción a la interpretación de esos dos valores y es que, por raro que parezca, en esta rama de las Matemáticas ni el cero ni el uno son siempre lo que parecen. Hay dos ceros y dos unos distintos.
¿Qué probabilidad hay de sacar un símbolo de Batman en un dado de 20 caras? Cero, ya que es imposible…¿o no? 😉 (Imagen del símbolo en dominio público).
Para entender de qué va este aparente sinsentido, te propongo un reto: ve al mercado más próximo e intenta encontrar una manzana que pese, exactamente, 200 gramos. Ya que las manzanas suelen pesar entre 150 y 230 gramos, no parece tarea imposible.
Tras una ardua búsqueda, es muy posible que des con alguna que se acerque mucho… pero
casi seguramente nunca encontrarás una que pese exactamente 200g. Piensa que el peso es una magnitud que puede tener decimales, lo que en matemáticas llamamos
un número real: una manzana puede pesar 200,01 gramos o 199,999999978 gramos y, aún así, seguirían existiendo
infinitos valores posibles entre esos pesos y el buscado.
Por lo tanto, sólo existe una posibilidad entre infinitas de encontrar nuestro objetivo. Haciendo una
interpretación frecuentista de la probabilidad podemos calcular la que corresponde al éxito en nuestra búsqueda:
[ Pleft( {Peso = 200g} right) = frac{{{text{Número de casos válidos}}}}{{{text{Número de posibles casos}}}} = frac{1}{infty } = 0 ]
Esto pinta mal… una probabilidad de cero. ¿Quiere esto decir que es imposible encontrar una manzana de 200 gramos exactos? ¡Para nada! En realidad no existe ninguna ley del Universo que prohíba que existan manzanas con esa propiedad. Así que, estrictamente hablando, sí que sería posible.
A esta aparente contradicción de una probabilidad de cero para describir un hecho no imposible me refería al empezar este artículo diciendo que, en Teoría de Probabilidades, hay “dos ceros distintos”: uno que denota hechos imposibles, y otro que denota hechoscasi seguramente imposibles. Aunque este último parezca un término un poco vago, tiene un significado matemático escrupulosamente preciso y muy bien definido, como veremos luego.
Pero sin recurrir a tecnicismos podemos entender intuitivamente estas dos versiones de una “probabilidad cero”:
-
P(X)=0 significa imposibilidad cuando el hecho X ni siquiera entra en la lista de posibles resultados de un experimento. Por ejemplo, el símbolo de Batman de arriba nuncaaparecerá al tirar los dados (¡si los dados son normales!).
-
P(X)=0 significa casi seguramenteimposibilidad cuando el hecho sí que entra entre los posibles resultados, pero se trata de un conjunto finito de posibilidades frente a un espacio de posibles resultados infinito. Fíjate en que he dicho conjunto finito. Si el reto de antes fuese encontrar una manzana de 200 gramos con una horquilla de ±1 gramos la historia cambiaría completamente: ahora también habría infinitasposibilidades válidas, con lo que la probabilidad de tener éxito será un número pequeño, pero mayor que cero.
Como quizás te hayas cuestionado ya en este punto, ¿qué ocurre con los hechos contrarios a los casi seguramente posibles? Es decir, ¿qué probabilidad existirá de que no encuentres una manzana del peso indicado?
Sabemos que si un hecho solamente puede cumplirse (X) o no cumplirse (¬X), la suma de ambas probabilidades debe ser uno ya que siempre se cumplirá o uno o el otro – esto es
un axioma de la Teoría de Probabilidades y es completamente razonable. Por ello, obtenemos que P(¬X)=1-P(X)=1-0=1. Y sí, existen
dos unos distintos, de forma complemente similar a los dos ceros que describí arriba:
-
Un P(Y)=1 para eventos que son seguros, p.ej. si suelto un objeto en la Tierra éste caerá hacia abajo, después de un día viene otro, la banca siempre gana, etc.
-
Y otro P(Y)=1 para eventos casi seguramenteseguros, como por ejemplo que fallarás al intentar dibujar una recta de exactamente un metro de larga.
Ahora, y sólo apto para aficionados a las Matemáticas, os dejo la explicación técnica del concepto de “casi seguramente” (“almost surely” en inglés).
Hay que empezar con la definición moderna (
Kolmogorov) de qué es el
espacio probabilístico, representado por una tupla de tres elementos:
( Ω ,F,P)
donde
Ω es el espacio muestral de todos los posibles valores de la variables que estamos analizando,
F es una
sigma-álgebra de
Ω (se puede entender como el conjunto de todos los posibles subconjuntos de
Ω) y
P, el elemento más importante, es una
medida que a cada posible elemento de
F le asigna un número entre 0 y 1:
lo que llamamos probabilidad. El concepto de
medida se resume en la asignación a cada F de una “medida” de “su tamaño”, y aunque parezca algo trivial, da lugar a la llamada
Teoría de la Medida, y es la base de la Teoría de Probabilidades moderna (~1950) que unificó el tratamiento de variables discretas y continuas.
A partir de la medida P se puede definir la probabilidad de que una variable aleatoria (unidimensional) sea menor que cualquier valor dado; en el ejemplo de arriba, P( PesoManzana < x ). Llamamos a esa importante función la función de distribución, F(x)=P(X < x). Y ahora, podemos obtener la probabilidad de que una variable X tenga exactamente un valor x cualquiera como la diferencia entre el valor de F(x) en ese punto y su límite por la izquierda:
[ Pleft( {X = x} right) buildrel wedge over = P(x) – {lim _{X to {x^ – }}}Pleft( X right) ]
=»»>
Veamos un ejemplo para ver en qué se concreta esta definición tan rara. Imaginemos un experimento cuyo resultado es un número real entre 1 y 5, y tal que su función de distribución sea como esta gráfica:
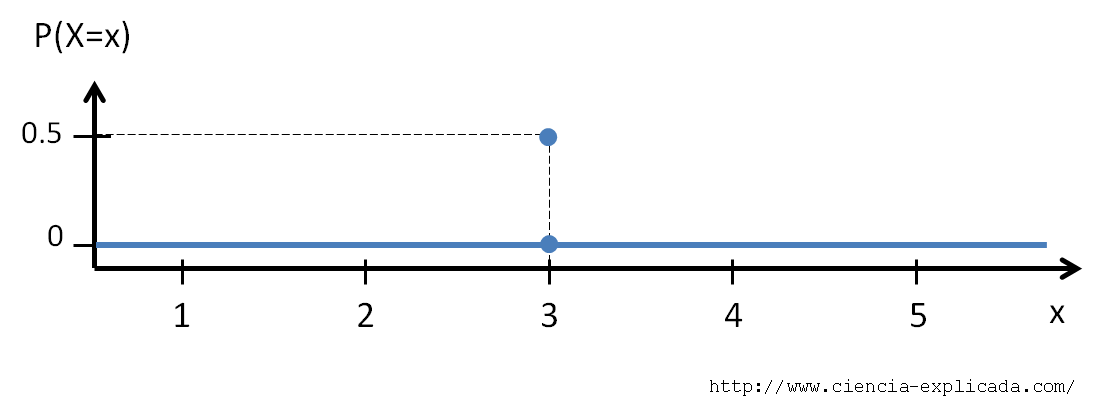
La bolita en el punto x=3 significa que en ese punto la gráfica es continua sólo por la izquierda. ¿Qué interpretación tiene esto? Pues que estamos ante un experimento extraño, en el que cualquier número real entre 1 y 5 tiene igual probabilidad de ocurrir… excepto para el número 3 que ocurrirá en el 50% de las ocasiones.
Aplicando la definición del límite que puse arriba para calcular la probabilidad de obtener cualquier número veremos que siempre obtendremos cero (lo lógico para cualquier función continua) excepto para el número 3:
Vemos por tanto como es posible que la probabilidad de obtener un 2 o un 4 sea de exactamente cero, a pesar de ser resultados perfectamente posibles: en eso consiste decir que casi seguramente nunca saldrá ni un 2 ni un 4.
Os dejo unas preguntas muy sencillas para los que sepan de probabilidad pero que seguro os harán reflexionar. Si la suma de las probabilidades de todos los posibles resultados debe dar un total de uno, ¿por qué sólo estamos viendo un 50% de los casos? ¿Qué pasa con el otro 50% que se ha esfumado? ¿Por qué si integramos P(X=x) sobre todos los valores obtenemos cero (ojo: todos esos ceros de la última gráfica no son valores infinitesimalmente pequeños, sino ceros exactos)? ¿Qué falta aquí? 😉
Este artículo se publicó en Amazings.es
[ Dedicado a JAFMA 😉 ]