La paradoja matemática de "forever alone": ¿por qué tengo menos amigos que los demás?

¿Me creerías si te digo que, muy probablemente, tienes menos amigos que los que te rodean? ¿O que te tocará esperar más que al resto en la cola del bar, el super o la gasolinera? No es que seas gafe, no: es lo que debe ocurrirnos a todos, aunque parezca paradójico. Y hoy traigo la sencilla demostración matemática.
 |
| El meme forever alone hoy se sentirá un poquito mejor gracias a la estadística. |
Piensa en un grupo de N personas: una clase de instituto o de la universidad, un equipo de fútbol, da igual.
Asumamos que el número de amigos que cada miembro del grupo tiene dentro de ese mismo grupo es un número al azar, por ejemplo, cualquier número entre 1 y 10 de forma que hay un 10% de probabilidades de que alguien tenga 1 amigo, otro 10% de que tenga 2, etc.
Con esa distribución tan «justa» e «igualitaria» del número de amigos, parecería lógico pensar que si cada uno comparáse el número de amigos con los de su entorno (con los de sus amigos), habrá aproximadamente un 50% de probabilidades de que tener más amigos que los demás y un 50% de tener menos.
Pues si tienes la paciencia de hacer el experimento, por ejemplo con tus contactos de Facebook o Tuenti, te llevarás una desagradable sorpresa: con muy alta probabilidad, ¡tendrás menos amigos que los demás!
Llamaré a esto (¿por qué no?) «la Paradoja de Forever Alone«.
Pero naturalmente el tema no es nada nuevo. Ya fue publicado, por ejemplo, en un artículo de 1991 titulado «Why your friends have more friends than you» (pdf), y es una versión más de la paradoja del «tamaño de la clase», bautizada así en 1977.
Empecemos numerando a cada miembro del grupo con la letra \( i \), de forma que \(i\) puede valer \(i=1\), \(i=2\) etc… hasta \(i=N\). Y al número de amigos que tiene el personaje \(i\) lo llamaremos \(a_i\).
Para verlo con un ejemplo, podemos dibujar un grupo de amigos en forma de grafo matemático, donde las líneas entre individuos (los arcos) indiquen que existe una relación de amistad:
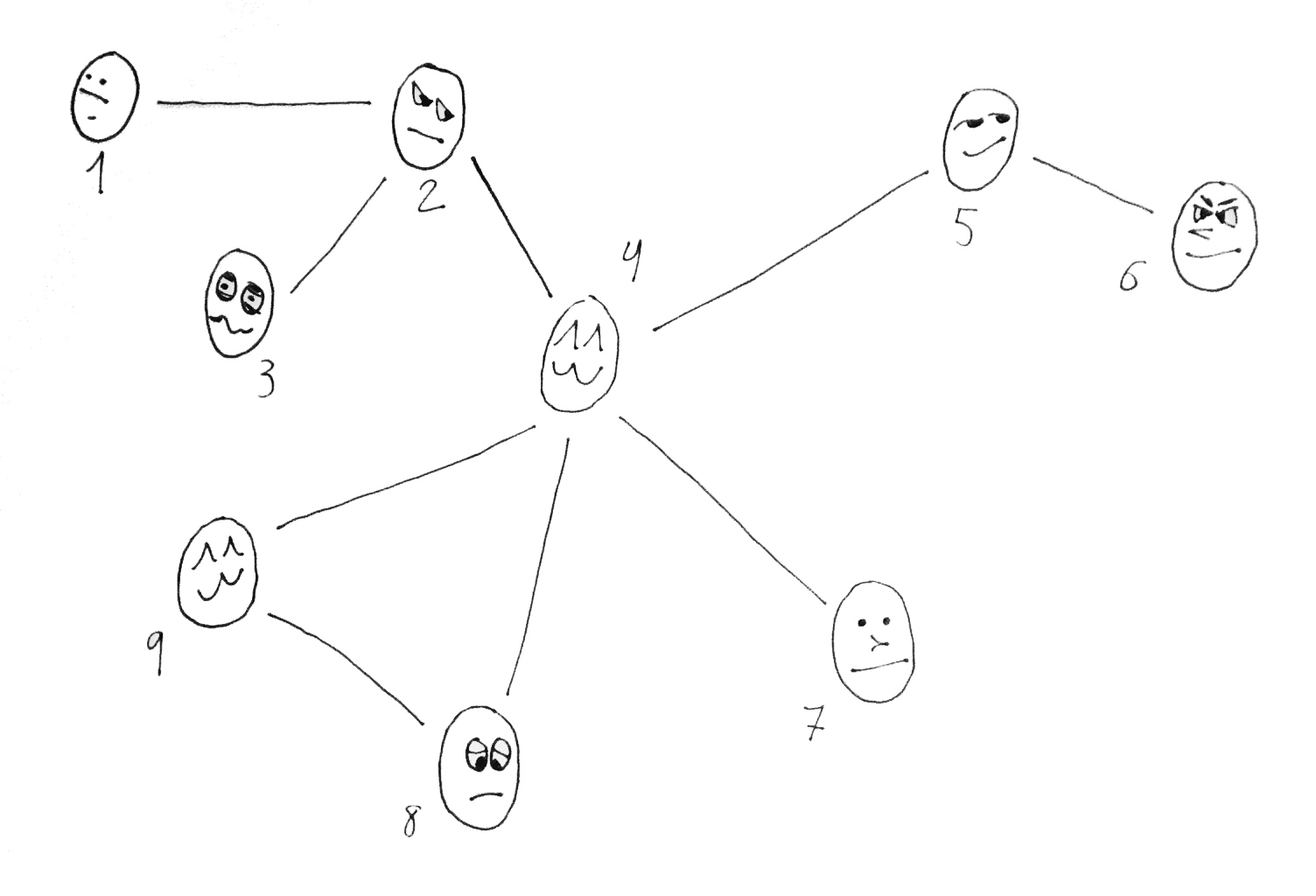
Aquí tenemos N=9 individuos, y el número de amigos \( a_i \) de cada uno será:
\(\begin{array}{|c|c|}\hline i & a_i \\ \hline 1 & 1 \\
2 & 3 \\
3 & 1 \\
4 & 5 \\
5 & 2 \\
6 & 1 \\
7 & 1 \\
8 & 2 \\
9 & 2 \\ \hline\end{array}\)
Para empezar, podemos preguntarnos cuál es el número medio de amigos en el conjunto del grupo. Este estadístico se llama media o esperanza matemática, y se escribe \(bar{a} \), o como el operador \( E[a_i] \) . La forma de calcularla seguro que todos la sabéis: se suman todos los valores y se divide por el número de valores. En nuestro ejemplo:
\(\hat{\bar{a}} = E[a_i] = \frac{1}{N} \sum_{i=1}^9 a_i = \frac{1+3+1+5+2+1+1+2+2}{9} = \frac{18}{9}= 2
\)
Otro estadístico que nos hará falta después es la varianza \(\sigma^2_a\), que nos dice cómo de dispersos están los valores de nuestra distribución: a menor valor, más cerca estarán todos los números de la media; a mayor valor, más diferencias habrá entre unos y otros.
Matemáticamente se define (para variables unidimensionales) como la esperanza de la diferencia al cuadrado de cada muestra con la media.
\(\sigma^2_a = E[\left(a_i – \bar{a}\right)^2]
\)
\begin{eqnarray}
\hat{sigma^2_a} &=& Eleft[left(a_i – hat{bar{a}}right)^2 right] = frac{1}{9-1} sum_{i=1}^9 left( a_i – bar{a} \right) = \
&& frac{1}{8} [ (1-2)^2+(3-2)^2+(1-2)^2+(5-2)^2+(2-2)^2+(1-2)^2+ \
&& (1-2)^2+(2-2)^2+(2-2)^2 ] = 1.75
end{eqnarray}
\)
hline
i & a_i & y_i&& & a_i < y_i ? \ hline
1 & 1 & (a_2)/a_1 = 3/1 &=& 3 & SI \
2 & 3 & (a_1+a_3+a_4)/a_2 = 7/3 &=& 2.33 & NO \
3 & 1 & (a_2)/a_3 = 3/1 &=& 3 & SI\
4 & 5 & (a_2+a_5+a_7+a_8+a_9)/a_4 = 10/5 &=& 2 & NO\
5 & 2 & (a_4+a_6)/a_5 = 6/2 &=& 3 & SI\
6 & 1 & (a_5)/a_6 = 2/1 &=& 2 & SI\
7 & 1 & (a_4)/a_7 = 5/1 &=& 5 & SI\
8 & 2 & (a_4+a_9)/a_8 = 7/2 &=& 3.5 & SI\
9 & 2 & (a_4+a_8)/a_9 = 7/2 &=& 3.5 & SI\
hline
end{array}\)
Vamos, que la media de los «amigos de mis amigos» es la media de amigos que tiene cualquier individuo… más otro término que depende de la varianza. Usando los números que sacamos arriba para el ejemplo, el número medio de amigos era de 2, mientras que el número medio de «amigos de amigos» sería de ( 2 + 1.75/2 = 2.875 ), claramente superior.
En otras palabras: si el individuo medio compara sus amigos \( bar{a} \) con los de sus amigos, tendrá que comparar ese valor con \( bar{y} \) y ¡siempre verá que su cifra es inferior! (la única excepción sería que todos tuvieran estrictamente idéntico número de amigos, con lo que la varianza se haría cero).
La demostración está muy bien, pero… ¿qué es lo que está pasando realmente?
Es fácil: un sesgo en el muestreo. Un observador externo que contara el número de amigos medio del total de la población y lo comparase con el de cada individuo, no observaría ninguna desviación con respecto a un lógico 50%/50% (si la distribución de amigos es simétrica, bla bla).
El truco de todo el asunto es que la pregunta «¿tengo más amigos que los demás?» se la hace cada uno, estimando los datos desde su punto de vista subjetivo y sin ver la imagen global. O dicho de otra forma: hay datos (el número de amigos de «los más populares») que serán contados muchas más veces sencillamente porque… ¡tienen muchos amigos en cuyos cálculos entran!
Todo esto tiene otra interpretación más bonita usando el concepto de distribución de masa de probabilidad (dmp). Llamemos \( P(n) = p_n \) a la probabilidad (en el conjunto de la población) de que alguien tenga ( n ) amigos. Pues curiosamente, si alguien intenta, desde su punto de vista subjetivo estimar dicha función, obtendrá una versión muy sesgada:
\( hat{P}(n) = p_n^2 \)Este problema se llamó en los años 70 el problema del «tamaño de la clase» porque explica que los alumnos, de media, tengan la sensación que les ha tocado las clases más abarrotadas. Si lo piensas, verás que tiene exactamente la misma razón que el problema de arriba.
Otro hecho curioso relacionado es el efecto «¿por qué siempre voy en el carril más lento?«. Aparte del lógico sesgo psicológico de fijarnos más en todo lo malo que nos ocurre e ignorar lo bueno (o al menos, «no malo») en este caso de nuevo estamos muestreando una distribución de probabilidad (¿cuántos coches hay en fila?) desde un punto de vista subjetivo: por definición, en el carril lento habrá más coches, luego tengo más probabilidades de estar en él.
 |
| (fuente) |
Así que, la próxima vez que vayas a quejarte porque «lo malo siempre me toca a mí«, reflexiona un momento a ver si estás siendo víctima del sesgo de muestreo. Vale, no es que sea de mucho alivio, pero…

